Prometheus este un serviciu de monitorizare a serverelor. El colectează metrici (valori) din serverele-țintă configurate, la anumite intervale prestabilite, evaluează anumite reguli și expresii, afișează rezultatele și poate declanșa alerte atunci când anumite condiții devin adevărate (utilizare excesivă a procesorului, sistemul a rămas fără memorie liberă, spațiu lipsă pe disc, etc.). În trecut, am mai prezentat Pinguzo și Netdata, alte două instrumente de monitorizare a serverelor web. Prometheus ridică, însă, monitorizarea la un alt nivel, mult mai complex.
Fac precizarea că, deși eu am folosit CentOS 7 atât pentru serverul Prometheus, cât și pentru serverele monitorizare (noduri), pașii de mai jos pot fi urmați pentru instalarea și configurarea Prometheus pe orice distribuție Linux cu systemd.
În tutorial nu voi explica fiecare comandă în parte, deoarece presupun că, dacă ați ajuns să citiți acest articol, ar trebui să aveți ceva cunoștințe Linux.
Pregătirea sistemului
Înainte de instalarea serverului Prometheus, trebuie avut grijă, în mod special, să fie setată sincronizarea NTP - timpul este o valoare sensibilă în analiza metricilor. Red Hat 7 (și derivatele sale) nu mai folosesc serviciul ntpd, ci chronyd - așa că instalați și configurați pachetul chrony (voi reveni într-un alt articol asupra sa).
Dacă aveți firewallul activat, trebuie să deschideți următoarele porturi:
- 9090 pentru Prometheus
- 9100 pentru node_exporter
- 3000 pentru Grafana
- 323 pentru chrony (asta dacă încă nu ați făcut-o deja)
În funcție de firewall, se rulează comenzile:
- pentru firewalld
# firewall-cmd --permanent --add-port=9090/tcp
# firewall-cmd --permanent --add-port=9100/tcp
# firewall-cmd --permanent --add-port=3000/tcp
# firewall-cmd --permanent --add-port=323/udp
# systemctl reload firewalld
# firewall-cmd --list-all
- pentru iptables:
Se editează fișierul /etc/sysconfig/iptables și se restartează iptables:
# vi /etc/sysconfig/iptables
Se adaugă regulile:
-A INPUT -p tcp -m state --state NEW -m tcp --dport 9090 -j ACCEPT
-A INPUT -p tcp -m state --state NEW -m tcp --dport 9100 -j ACCEPT
-A INPUT -p tcp -m state --state NEW -m tcp --dport 3000 -j ACCEPT
# systemctl restart iptables
Instalarea serverului Prometheus
Vom instala Prometheus în directorul /opt:
# cd /opt
Navigați la https://prometheus.io/download/ și descărcați ultima versiune a binarelor Prometheus pentru Linux (în momentul scrieii acestui articol, ultima versiunea este 2.2.1):
# wget https://github.com/prometheus/prometheus/releases/download/v2.2.1/prometheus-2.2.1.linux-amd64.tar.gz
# tar -zxvf prometheus-2.2.1.linux-amd64.tar.gz
# ln -s prometheus-2.2.1.linux-amd64 prometheus# useradd -r -s /sbin/nologin prometheus
# chown -R prometheus:prometheus /opt/prometheus-2.2.1.linux-amd64/
Crearea serviciului Prometheus
# vi /etc/systemd/system/prometheus.service
În interiorului noului fișier vom scrie următoarele:
[Unit]
Description=Prometheus Server
Documentation=https://prometheus.io/docs/introduction/overview/
After=network-online.target
[Service]
User=root
Restart=on-failure
ExecStart=/opt/prometheus/prometheus --config.file=/opt/prometheus/prometheus.yml
[Install]
WantedBy=multi-user.target
Rularea serverului Prometheus
Se rulează comenzile:
# ln -s /opt/prometheus/prometheus.yml /etc
# systemctl daemon-reload
# systemctl enable --now prometheus
# systemctl status prometheus
Vizualizarea metricilor
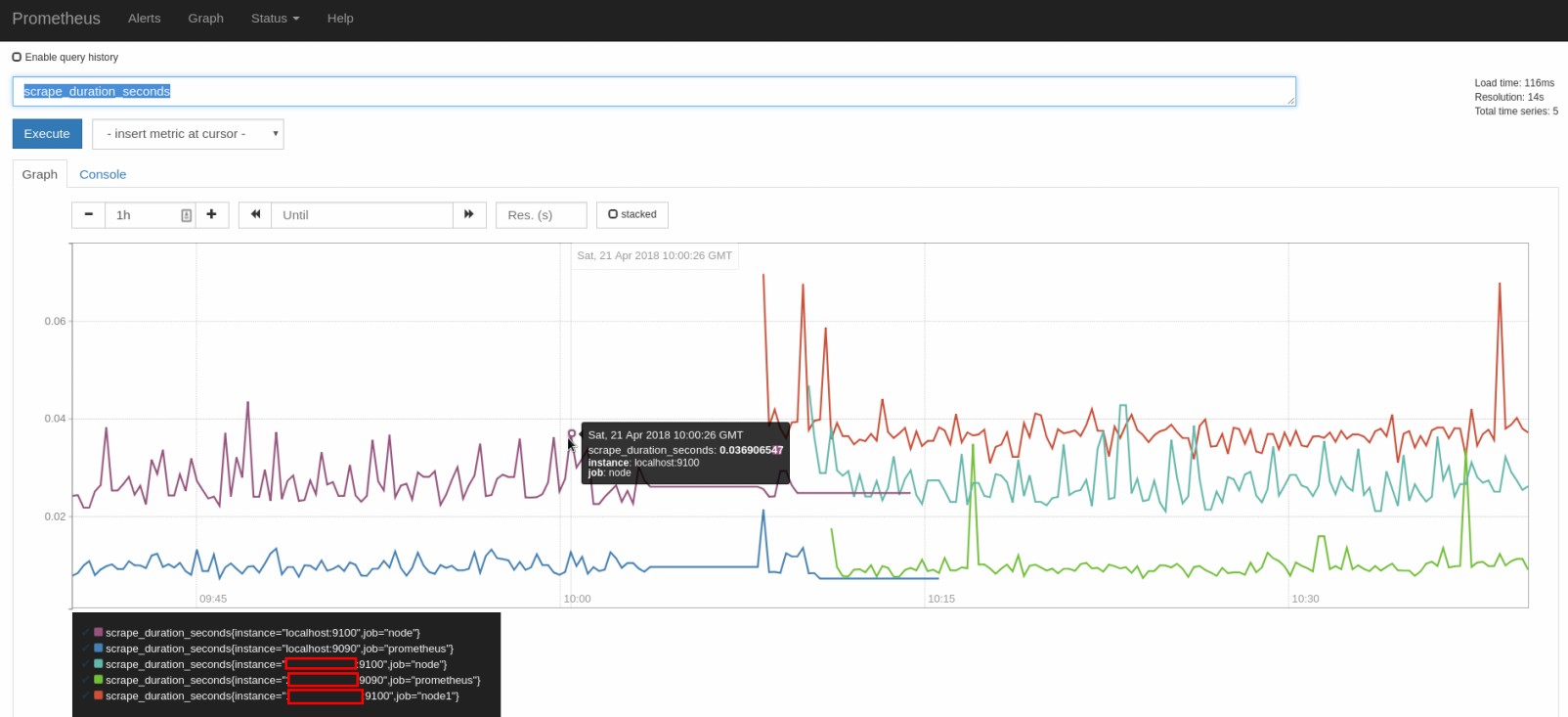
În browser, se merge la adresa http://IP_server_prometheus:9090. Click pe Graph; introduceți expresia scrape_duration_seconds și click pe Execute:
Instalarea Node Exporter
Node Exporter se instalează pe fiecare server care va fi monitorizat (atenție la portul 9100!). Vom instala Node Exporter tot în directorul /opt; vom descărca ultima versiune Node Exporter (în momentul scrierii acestui articol, ultima versiune stabilă Node Exporter este 0.15.2):
# cd /opt
# wget https://github.com/prometheus/node_exporter/releases/download/v0.15.2/node_exporter-0.15.2.linux-amd64.tar.gz
# tar xvfz node_exporter-*.tar.gz
# rm node_exporter-0.15.2.linux-amd64.tar.gz
# ln -s node_exporter-0.15.2.linux-amd64 node_exporter
# chown -R prometheus:prometheus /opt/node_exporter-0.15.2.linux-amd64
Crearea serviciului Node Exporter
Vom face un fișier nou în /etc/systemd/system:
# vi /etc/systemd/system/node_exporter.service
În acest fișier nou vom scrie următoarele (opțiunea --no-collector.disktats a fost adăugată deorece aceste statistici nu funcționează pe sistemele virtualizate - sunteți liberi să scoateți această opțiune, dacă doriți):
[Unit]
Description=Node Exporter
[Service]
User=root
ExecStart=/opt/node_exporter/node_exporter --no-collector.diskstats
[Install]
WantedBy=default.target
Pornirea serviciului node_exporter:
# systemctl daemon-reload
# systemctl enable --now node_exporter
# systemctl status node_exporter
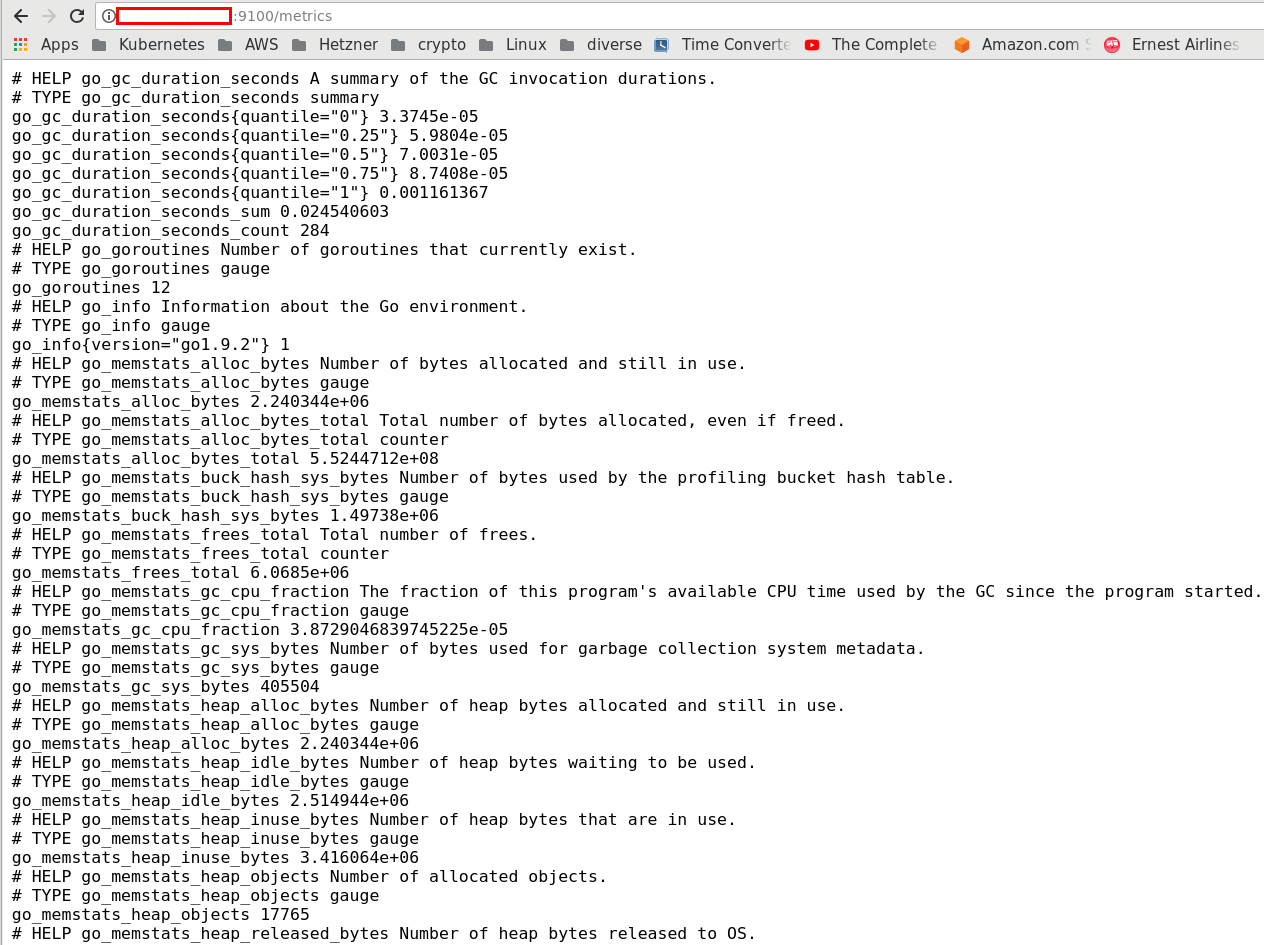
În acest moment, dacă navigați în browser la adresa http://IP_server:9100, veți vedea o pagină pe care scrie Node Exporter și un link numit Metrics, care conține toate metricile aferente sistemului (nodului) monitorizat. Click pe Metrics și veți vedea ceva ca mai jos:
Acum, trebuie să-i spunem lui Prometheus să citească aceste metrici. Pe serverul unde am instalat Prometehus, edităm fișierul /opt/prometheus/prometheus.yml:
# vi /opt/prometheus/prometheus.yml
Adăugăm la final următoarele rânduri:
- job_name: 'node'
static_configs:
- targets: ['localhost:9100']
Această secvență se adaugă pentru fiecare server unde este instalat Node Exporter (localhost se înlocuiește cu IP-ul serverului respectiv); de asemenea, job_name: 'node' se transformă în job_name: 'node1', etc. - sau ce nume vreți voi să-i dați. Sau nodurile/serverele se pot adăuga unul după altul, ca în exemplul de mai jos:
- job_name: 'nodes'
static_configs:
- targets: ['IP_server_01:9100', 'IP_server_02:9100']
Atenție! Acest fișier este de tipul yaml și este foarte sensibil la formatare! Pentru a verifica dacă este corect scris, folosiți un tool pentru validare (de exemplu ăsta: yaml validator).
După editarea și salvarea acestui fișier, restartați serviciul prometheus și verificați statusul său:
# systemctl restart prometheus
# systemctl status prometheus
Serviciul trebuie să fie activ. Dacă nu este activ, aproape sigur problema este la fișierul de configurare (probabil nu este corect formatat yaml). Pentru a vedea exact ce se întâmplă, puteți să aruncați un ochi în fișierul /var/log/messages:
# less /var/log/messages
S-ar putea să vedeți ceva de genul erorii de mai jos (vă spune exact unde este problema - probleme cu formatarea fișierului de configurare):
err="Error loading config couldn't load configuration (--config.file=/opt/prometheus/prometheus.yml): parsing YAML file /opt/prometheus/prometheus.yml: yaml: line 29: did not find expected '-' indicator"
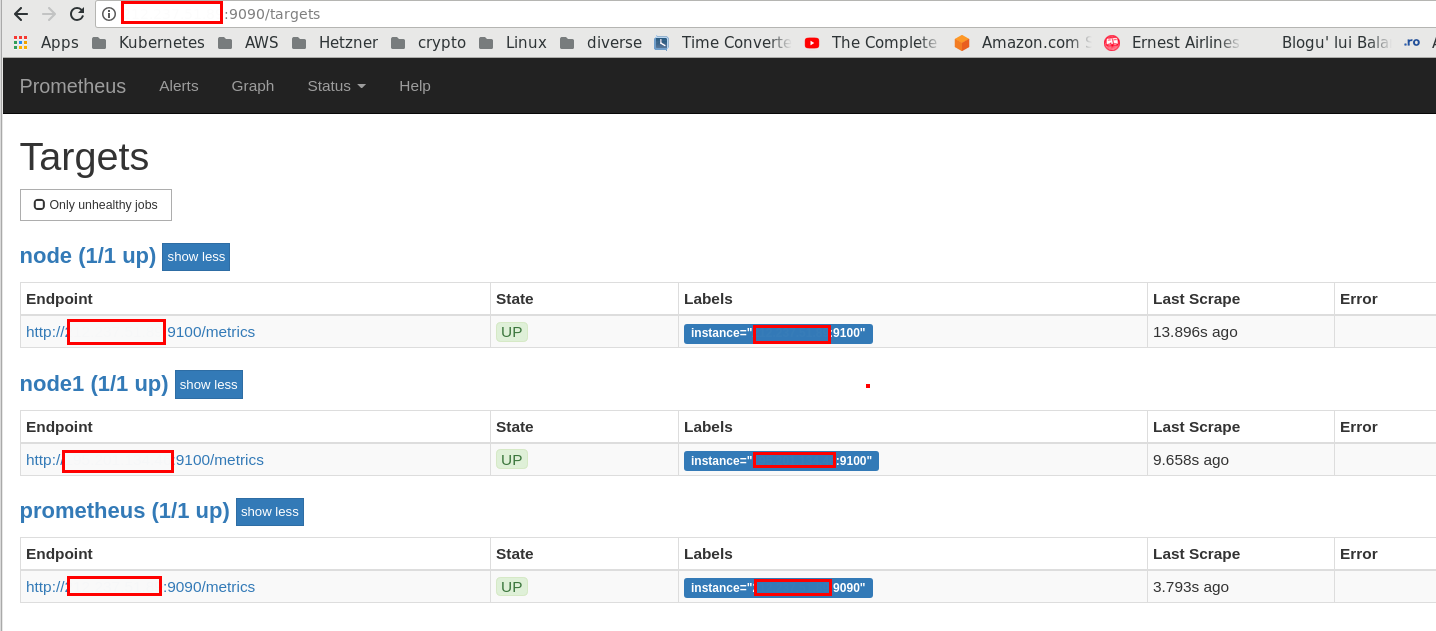
După ce ați adăugat toate nodurile unde ați instalat Node Exporter și pe care vreți să le urmăriți prin intermediul Prometheus, navigați, în browser, la adresa http://IP_server_prometheus:9090/targets și veți putea observa statusul fiecărui server:
Pachete RPM
O posibilitate mai ușoară de instalare Prometheus, Alertmanager și Node Exporter este să adăugăm repository-ul adecvat:
# vi /etc/yum.repos.d/prometheus.repo
Adăugăm următoarele:
[prometheus] name=prometheus baseurl=https://packagecloud.io/prometheus-rpm/release/el/7/$basearch repo_gpgcheck=1 enabled=1 gpgkey=https://packagecloud.io/prometheus-rpm/release/gpgkey https://raw.githubusercontent.com/lest/prometheus-rpm/master/RPM-GPG-KEY-prometheus-rpm gpgcheck=1 sslverify=1 sslcacert=/etc/pki/tls/certs/ca-bundle.crt metadata_expire=300
Pentru a instala Prometheus și alertmanager:
$ sudo yum install prometheus2 alertmanager
Pentru a instala Node Exporter pe docurile pe care vrem să le monitorizăm:
$ sudo yum install node_exporter
Pornirea serviciilor:
sudo systemctl enable --now prometheus
sudo systemctl enable --now alertmanager
sudo systemctl enable --now node_exporter
Instalare Grafana
Interfața default a lui Prometheus este destul de simplă. Dar, mulțumită integrării Prometheus cu Grafana, putem obține o interfață grafică mult mai plăcută și interesantă.
Pentru a instala Grafana local, pe serverul unde am instalat Prometheus, avem mai multe posibilități: fie descărcam ultima versiune și o instalăm manual, fie folosim un repo pentru Grafana (am preferat ultima variantă):
# vi /etc/yum.repos.d/grafana.repo
Adăugăm următoarele:
[grafana]
name=grafana
baseurl=https://packagecloud.io/grafana/stable/el/7/$basearch
repo_gpgcheck=1
enabled=1
gpgcheck=1
gpgkey=https://packagecloud.io/gpg.key https://grafanarel.s3.amazonaws.com/RPM-GPG-KEY-grafana
sslverify=1
sslcacert=/etc/pki/tls/certs/ca-bundle.crt
# yum update
# yum install grafana
# systemctl daemon-reload
# systemctl enable --now grafana-server
# systemctl status grafana-server
Pentru instalarea Grafana pe alte distribuții click aici.
Configurare Grafana
Fișierul de configurare pentru Grafana este /etc/grafana/grafana.ini - aici putem configura, de exemplu, detalii SMTP pentru trimiterea alertelor (în secțiunea SMTP trecem enabled = true).
- navigăm la adresa http://IP_server_prometheus:3000
- credențialele default sunt admin - admin; se recomandă crearea unui user nou, cu o parolă puternică și ștergerea userului admin;
- crearea Prometheus data source:
- click pe logo Grafana
- click pe Data Source
- click pe Add new
- selectarea Prometheus ca tip
- setarea url-ului adecvat pentru Prometheus (de exemplu, http://IP_server_prometheus:9090)
- ajustarea setărilor dorite data source (de exemplu, accesarea directă sau prin proxy)
- click pe Add pentru a salva

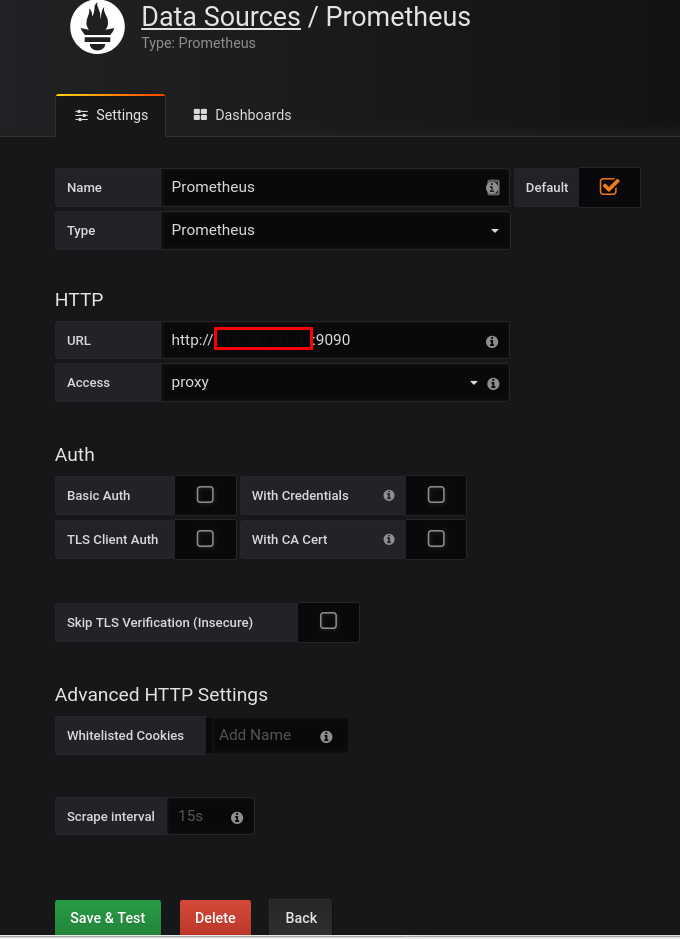
Crearea graficelor Prometheus
Se merge în meniul Dashboard și se selectează Import pentru dashboard-urile implicite:
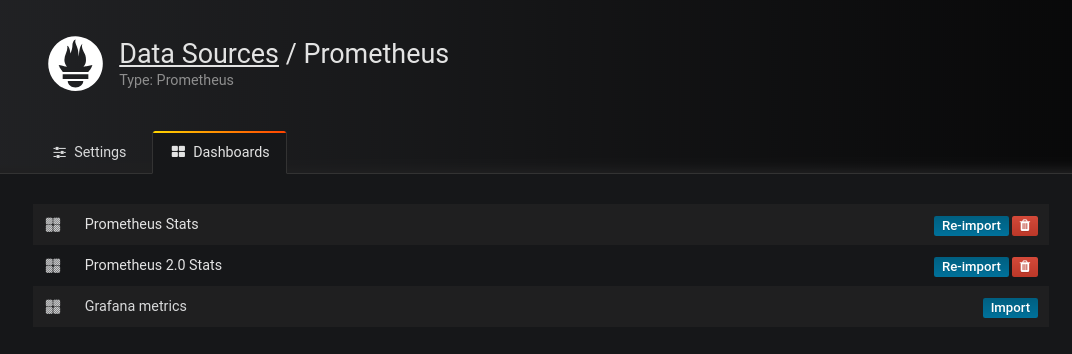
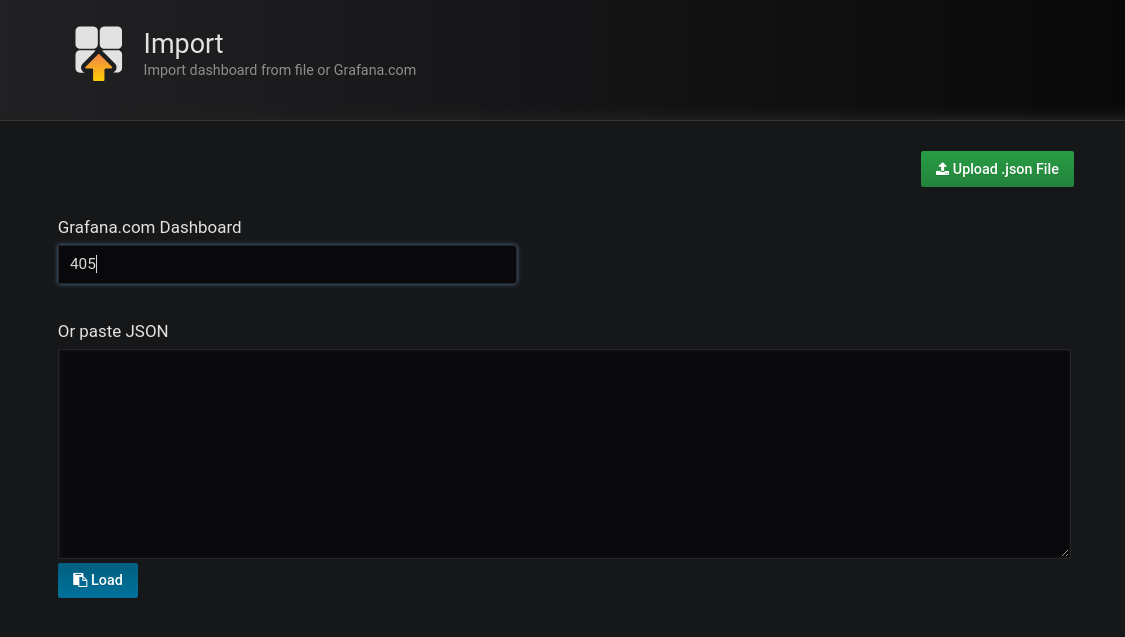
Importăm dashboard-ul Node Exporter Server Metrics furnizând id-ul dashboard-ului: 405 (New dashboard - Import dashboard) - este un dashboard care colectează datele din nodurile/serverele configurate în Prometheus, afișează aceste valori sub formă de grafice și poate trimite alerte atunci când anumite valori sunt depășite:
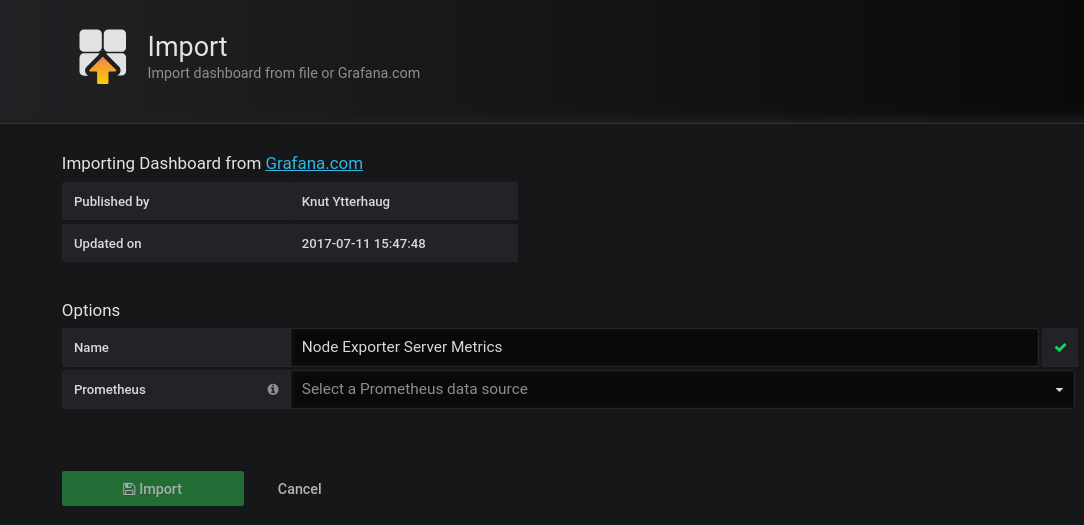
Acum, putem vedea valorile corespunzătoare procesorului, memoriei, etc. pentru fiecare nod/server monitorizat. După cum se vede în imaginea de mai jos, există posbilitatea selectării fiecărui nod, dar și cea a selectării perioadei care ne interesează: de la ultimele 5 minute, până la ultimii 5 ani.
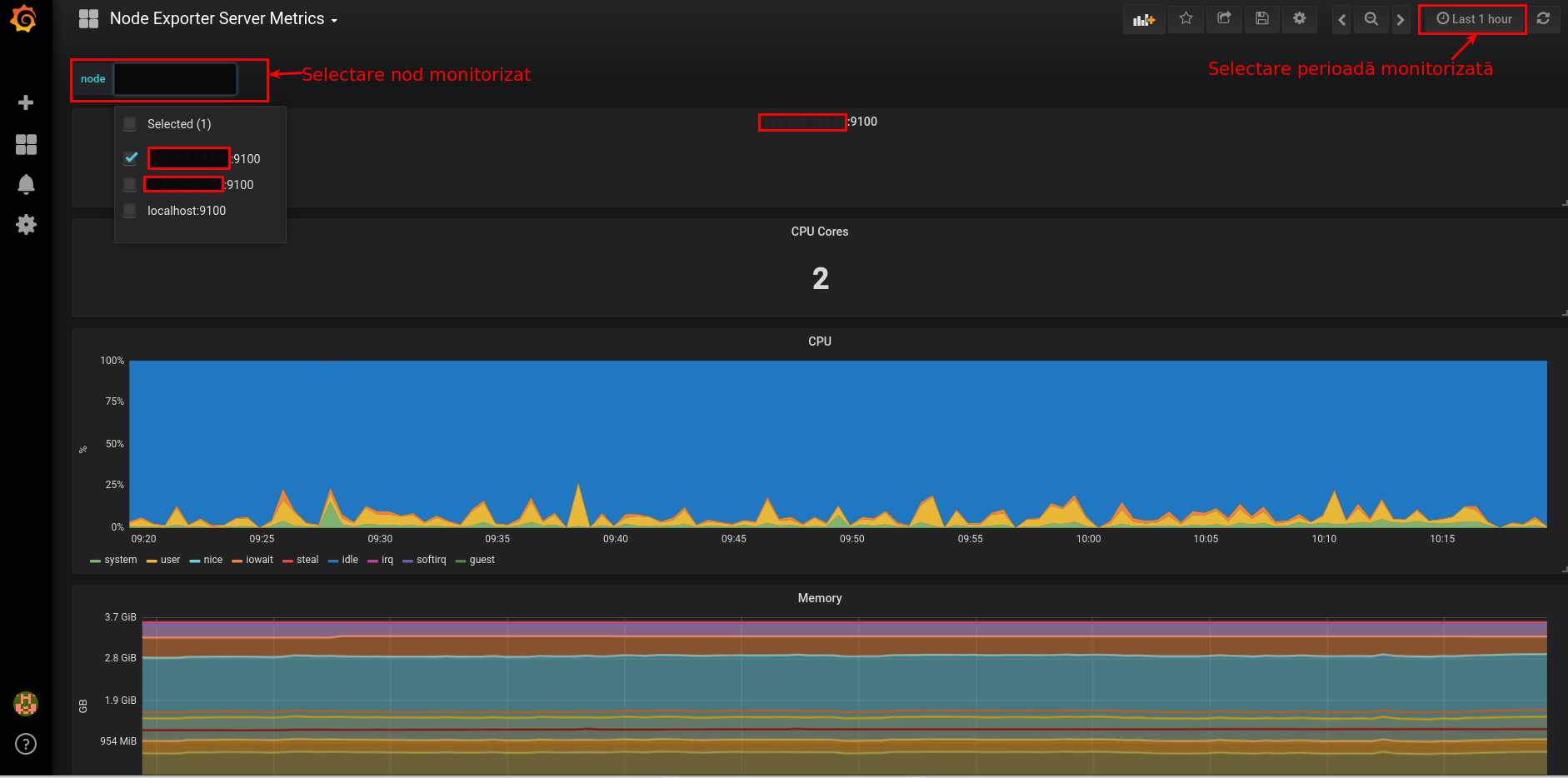
Puteți importa și alte dashboard-uri în Grafana - o listă completă a dashboard-urilor publice Grafana pentru Prometheus găsiți aici.
Configurarea alertelor în Grafana
Atât Prometheus, cât și Grafana, au posibilitatea de configurare a alertelor. Alertele în Grafana sunt foarte simplu de configurat. În general, pentru a configura alertele pentru un dashboard creat, se urmează pașii de mai jos (pentru ca alertele să funcționeze, trebuie configurată secțiunea SMTP din fișierul /etc/grafana/grafana.ini):
- se merge la Alerting/ Notification channels
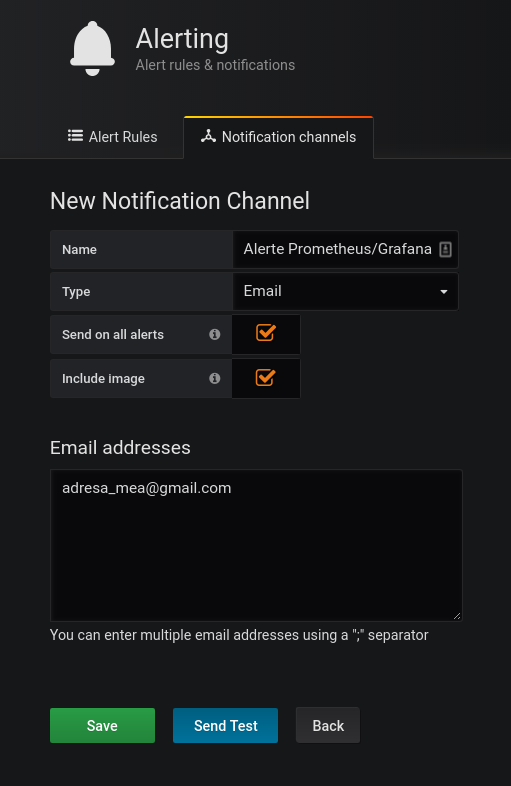
- click pe Add Channel
- dați un nume alertei și furnizați adresa de email (de aici puteți trimite și un email de test, ca să vă asigurați că mesajele de alertare sunt trimise)
- se merge înapoi în dashboard-ul Node Exporter Server Metrics
- click pe primul panou să-l selectăm, apoi click pe Edit din meniul care se deschide deasupra panoului
- click pe tabul Alert, apoi pe Create Alert
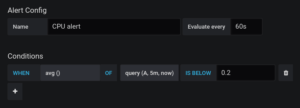
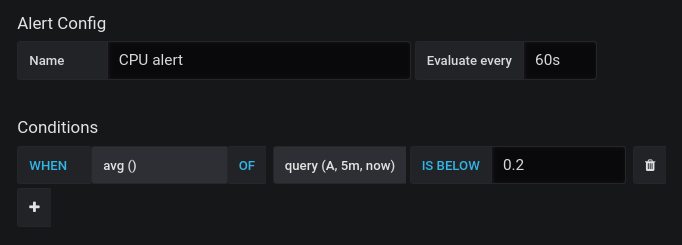
- configurăm alerta folosind următoarele condiții (pentru mult mai multe detalii despre alertele Grafana click aici)
- se selectează tabul Notification din partea dreaptă
- la Send to selectăm canalul de notificare creat mai sus
- scrieți un mesaj care să fie simplu și să descrie cât mai bine alerta (ex.: valoare mare de utilizare CPU)
- salvați dashboard-ul (sau CTRL+S)
Documentație completă Prometheus și Grafana.
Eu am preferat instalarea Prometehus și Grafana pe un server diferit de cele monitorizate - am ales un VPS ieftin (1€/lună), cu 1 GB RAM de la arubacloud.com.
Spor la configurat și testat!
Câteva exemple de alerte și fișiere de configurare pot fi văzute aici.
Sunteți invitați să lăsați în comentarii orice alte informații suplimentare și configurări cunoașteți pentru Prometheus și/sau Grafana.
Salut, cred ca este ceva in neregula cu crearea serviciului node exporter.
Primesc o eroare in momentul in care incerc sa o pornesc.
Salut. Nimeni nu te poate ajuta dacă nu spui și care este eroarea...
Salut, imi cer scuze, eu am gresit la crearea fisierului pentru serviciul node exporter.
Totul functioneaza cum trebuie.
Super! Spor!
Si eu vreau de ceva vreme sa le pun, dar n-am gasit timpul necesar ca sa fac asta si sa integrez toate VM-urile. Inca n-am reusit sa integrez log-urile de la VM-uri in Graylog asa ca o sa pun linkul tau la bookmark 🙂
Spor!
Deși îmi place să verific în mod clasic logurile, mă gândeam la o soluție Elasticsearch + Kibana. Sper să am timp să testez ambele variante (Kibana și Graylog).