Se întâmplă să vă conectați la un server Linux cu probleme de performanță: ce trebuie verificat în primul minut? În acest post (și următorul) voi prezenta 10 comenzi care trebuie date în primul minut după conectarea la un server Linux cu probleme de performanță. Voi încerca, pe cât posibil, să scriu mai multe articole despre analiza performanței în Linux.
Primele 60 de secunde ar trebui să fie suficiente pentru a ne da seama (măcar în linii mari) despre ce se întâmplă pe serverul respectiv. Ne vom uita la erori sau anumite valori care depășesc limitele acceptate, precum și după resursele utilizate. Vom căuta acele valori care arată că o anumită resursă are o încărcare peste limită și care poate fi afișată, de regulă, ca timp petrecut în așteptare (saturație).
uptime ----------------------------------------------------------> load average
dmesg | tail ---------------------------------------------------> kernel errors
vmstat 1 --------------------------------------------------------> overall stats by time
mpstat -P ALL 1 ---------------------------------------------> CPU balance
pidstat 1 --------------------------------------------------------> process usage
iostat -xz 1 -----------------------------------------------------> disk I/O
free -m ----------------------------------------------------------> memory usage
sar -n DEV 1 --------------------------------------------------> network I/O
sar -n TCP,ETCP 1 ------------------------------------------> TCP stats
top ---------------------------------------------------------------> check overview
Unele din aceste comenzi necesită instalarea pachetului sysstat (pachetul instalează o colecție de unelte de monitorizare a performanței: iostat, isag, mpstat, pidstat, sadf, sar). Valorile furnizate de aceste comenzi ne vor ajuta să localizăm sursa și cauza blocajelor pe serverul Linux. Aceasta presupune verificarea utilizării, saturației și a erorilor tuturor resurselor (CPU, memorie, disk, rețea, etc.).
În cele ce urmează voi prezenta pe scurt comenzile de mai sus, cu exemple de pe serverul unde am găzduit acest site. Mult mai multe puteți afla folosind binecunoscuta comandă man.
1. uptime
$ uptime
21:25:13 up 87 days, 3:48, 1 user, load average: 0.79, 1.00, 1.04
Este o modalitate rapidă de a vedea încărcarea medie, care sugerează numărul de task-uri (rpocese) care doresc să ruleze pe serverul respectiv. Aceste sunt atât procese care folosesc procesrul, cât și numărul de I/O pe disc. Aceste valori ne dau o idee despre încărcarea resurselor, dar nu pot fi înțelese în totalitate fără alte unelte.
Ceele 3 valori load average ne arată o medie a încărcării sistemului în ultimul minut, în ultimele 5 minute și în ultimele 15 minute. Valorile ne dau o idee despre ceea ce s-a întâmplat pe sistemul nostru în timp. De exemplu, dacă valoarea din ultimul minut este mult mai mică decât cea din ultimlele 15 minute, înseamnă că ne-am logat prea târziu și am pierdut partea "frumoasă" a ceea ce s-a întâmplat. 🙂 Valorile mele sunt ok, deci nu are rost să-mi fac griji.
2. dmesg | tail
$ dmesg | tail
[27568481.644011] [UFW BLOCK] IN=venet0 OUT= MAC= SRC=xxxx:2f08:60f0:xxxx:0914:43fd:b4f0:xxxx DST=2a05:91c0:xxxx:0000:0000:0000:9f85:xxxx LEN=72 TC=0 HOPLIMIT=55 FLOWLBL=0 PROTO=TCP SPT=47984 DPT=443 WINDOW=489 RES=0x00 ACK FIN URGP=0
[...]
[27568890.355506] [UFW BLOCK] IN=venet0 OUT= MAC= SRC=163.xxx.172.xxx DST=185.xxx.xxx.118 LEN=435 TOS=0x00 PREC=0x00 TTL=52 ID=28698 DF PROTO=UDP SPT=5062 DPT=5086 LEN=415
Această comandă ne arată ultimele 10 mesaje de sistem. Vom căuta erori care pot cauza probleme de performanță: de exemplu, ne vom uita după mesaje tip Out of memory sau mesaje de eroare pe TCP.
3. vmstat 1
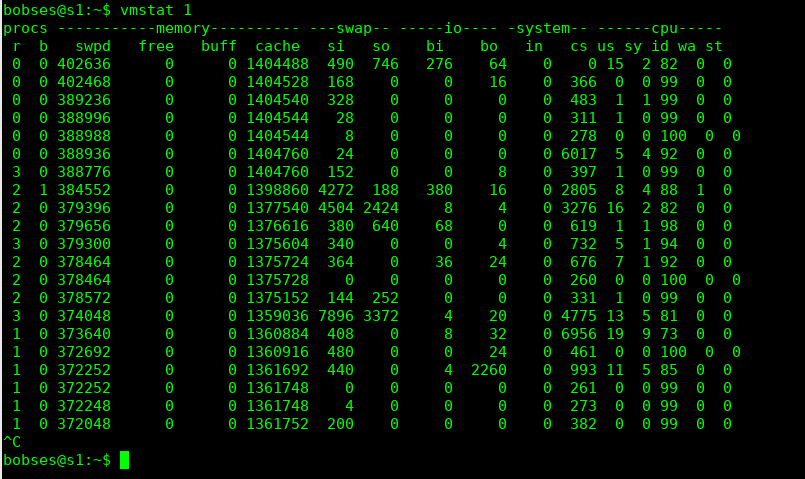
Virtual Memory Stat (vmstat) este un instrument disponibil întotdeauna pe sistemele Linux. Afișează un sumar al statisticilor serverului pe fiecare linie. vmstat rulează cu argumentul 1 pentru a afișa sumarul la 1 secundă.
Procese
- r - numărul proceselor care rulează (sau care așteaptă să ruleze). O valoare care poate arăta saturația procesorului - un număr mai mare decât numărul de nuclee ale procesorului înseamnă saturație
- b - numărul proceselor care "dorm"
Memorie
- swpd: cantitatea de memorie virtuală folosită
- free: memoria în așteptare (liberă)
- buff: cantitatea de memorie folosită ca buffer
- cache: cantitatea de memorie folosită drept cache
Swap
si, so - swap-in și swap-out; dacă aceste valori sunt diferite de zero, înseamnă că ne apropie de OOM (out of memory) - se pare că serverul meu suferă de această problemă.
I/O
bi, bo - blocuri de date primite de la un device sau trimise către un device
CPU
us, sy, id, wa, st - procente din timpul total de procesor (us - user time - timp în care procesorul rulează cod care nu este în kernel; sy - system time - timp în care procesorul rulează kernel code; id - idle time; wa - wating for I/O, adică așteaptă scririle/citirile de pe disc)
O valoare mare a timpului de procesor (user și system time) confirmă că procesorul este busy. O valoare constantă a wa (wait for I/O) ne arată probleme ale discului, deoarece sarcinile sunt blocate în așteptarea scrierii pe disc. Putem considera wa ca fiind o altă formă de CPU idle, dar una care ne dă și un indiciu de ce procesorul este "în așteptare".
O valoare mare a system time (sy) - peste 20% - poate să ne arat, de exemplu, că I/O sunt procesate ineficient de kernel.
În exemplu de mai sus, procesorul este, în cea mai mare parte a timpului, în starea "idle", ceea ce nu reprezintă o problemă.
4. mpstat -P ALL 1
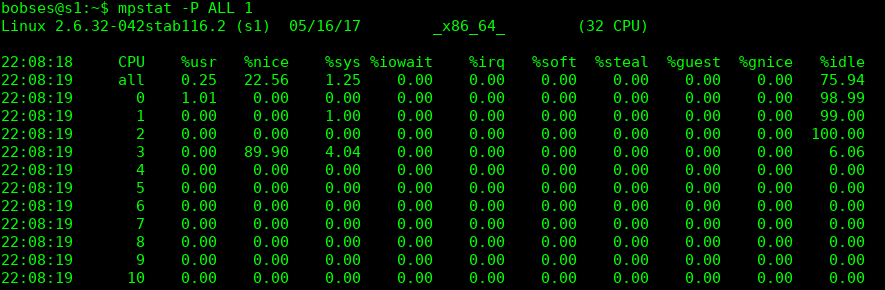
Această comandă arată detaliat timpul de procesor,după care putem determina un anumit dezechilibru.
La CPU, cuvântul cheie all arată cu statisticile sunt calculate ca medie pentru toate procesoarele din sistem.
- %usr - arată procentul de procesor folosit de utilizator (aplicații)
- %nice - procentul procesorului care este folosit în timp ce execută cu un anumit nivel de prioritate (nice)
- %idle - arată procentul de timp cât procesorul a stat "în așteptare" sau cât timp procesorul nu a avut cereri mari I/O.
[…] sosit week-end-ul, a venit și timpul părții a doua a articolului despre Perfomanța în Linux și primele 60 de secunde după conectarea la un […]