Operatorii au fost introduși de CoreOS și prezentați ca o clasă de software care operează alt software. Cine este curios și dorește să afle mai multe, poate citi prima postare în care au fost prezentați operatorii de către CoreOS. Articolul de față se ocupă exclusiv de Prometheus Operator.
Scurtă prezentare a Operatorului Prometheus
Prometheus Operator are ca scop rularea Prometheus (cu toate componentele sale) într-un cluster Kubernetes, funcționare ușoară, fără complicații și fără multă bătaie de cap. Operatorul Prometheus oferă definiții ușor de monitorizat pentru serviciile Kubernetes, precum și implementarea și managementul instanțelor Prometheus.
După instalare, Operatorul Prometheus oferă următoarele caracteristici:
- lansare extrem de ușoară a unei instanțe Prometheus într-un namespace K8s;
- configurare simplă a Prometheus-ului, ca de exemplu stabilirea versiunii, persistenței, politicilor de retenție ori replici a unei resurse native Kubernetes;
- configurare simplă pentru Alertmanager;
- gernerează automat configurații de monitorizare bazate pe etichete Kubernetes.
Cum funcționează Prometheus Operator
Ideea principală a operatorului a fost să decupleze deployment-ul instanțelor Prometheus de configurarea entităților pe care le monitorizează. Pentru a realiza acest lucru, au fost definite următoarele 2 resurse third party: Prometheus și ServiceMonitor.
Operatorul se asigură în permanență că fiecare resursă Prometheus definită în cluster funcționează cu configurația dorită. Aspecte ca timpul de retenție, numărul de replici, pvc (persistent volume claims), versiunea Prometheus, instanțele Alertmanager pentru trimiterea alertelor sunt controlate și monitorizate de Operator.
Utilizatorul poate specifica manual configurația dorită sau poate lăsa operatorul să o genereze în funcție de a doua resursă third party - ServiceMonitor. Resursa ServiceMonitor specifică câte metrici pot fi cerute dintr-un set de servicii expuse. Operatorul configurează instanța Prometheus să monitorizeze toate serviciile acoperite de ServiceMonitors și păstrează această configurație sincronizată cu orice schimbare petrecută în clusterul K8s.
Acest articol nu intenționează să descrie în amănunt funcționarea Operatorului Prometheus, ci doar instalarea lui și câteva elemente de configurare. Pentru mai multe amănunte, poate fi citit primul articol care a anunțat apariția operatorului Prometheus, pagina de git CoreOS sau pagina de git Helm.
Totuși, înainte de a începe instalarea Prometheus Operator, menționez că se instalează următoarele 4 CRD (Custom Resource Definitions), pe baza cărora, ulterior, pot fi create alte resurse:
- Prometheus - definește un deployment Prometheus în clusterul Kubernetes; operatorul se asigură în permanență că deployment-ul creat funcționează conform definiției CRD;
- ServiceMonitor - specifică grupurile de servicii care pot fi monitorizate. Operatorul generează automat configurația necesară pentru ca Prometheus să facă scrape conform definiției cerută de CRD;
- PrometheusRule - definește regulile Prometheus, reguli care se încarcă de o instanță Prometheus;
- Alertmanager - definește deployment-ul dorit pentru Alertmanager. Operatorul se asigură în permanență că acest implementarea Alertmanagerului funcționează conform definiției furnizate de CRD.
Trebuie reținut că, după ștergerea unui deployment Prometheus Operator instalat cu Helm, aceste CRD-uri trebuie șterse manual (nu sunt gestionate de către Helm) - în caz contrar, o instalare ulterioară nu va putea fi făcută.
Cerințe înainte de instalare
Normal, avem de nevoie, în primul rând , de un cluster Kubernetes :). Acesta poate fi configurat în cloud folosind diverse servicii (AWS, GCE) sau local, folosind fie mașini virtuale, fie minikube.
În al doilea rând, avem nevoie de Helm - este cea mai simplă modalitate de instalare și menținere a Operatorului Prometheus.
Instalarea Prometheus Operator
Este indicat să instalăm Prometheus Operator într-un namespace special destinat în cadrul clusterului K8s - astfel, putem gestiona mai ușor resursele generate de operator.
Vom face un nou namespace monitoring în Kubernetes:
$ kubectl create ns monitoring
namespace/monitoring created
Vizualizăm namespace-urile curente:
$ kubectl get ns NAME STATUS AGE default Active 99m kube-public Active 99m kube-system Active 99m monitoring Active 74s
Verificăm în chart-urile Helm existența Operatorului Prometheus:
NAME CHART VERSION APP VERSION DESCRIPTION
stable/prometheus-operator 1.9.0 0.26.0 Provides easy monitoring definitions for Kubernetes servi…
În acest moment, trebuie să avem în vedere că toate serviciile instalate de operator vor fi de tip ClusterIP, deci va fi nevoie să facem port-forward pentru a accesa de pe sistemul local Prometheus sau Alertmanager. Pentru a evita asta, vom descărca fișierul values.yaml de aici și îl vom edita astfel (facem o căutare după ClusterIP:
- vom schimba tipul serviciului Alertmanager din ClusterIP în NodePort (în prezent, schimbarea se face la linia 147) - reținem portul 30903 (nu este neapărat necesar, căci îl vom afla ulterior după afișarea tuturor serviciilor din namespace-ul monitoring);
- vom schimba tipul serviciului Prometheus din ClusterIP în NodePort (în prezent, schimbarea se face la linia 664); de asemenea, vom schimba și portul din 39090 (cât este definit în fișier) într-un port mai mic de 32767, de exemplu în 30090 - în prezent, schimbarea se face la linia 656.
Dacă doriți, puteți da un nume oarecare deployment-ului Prometheus Opăerator care va fi instalat (asta deoarece Helm acordă nume aleatorii, nume care nu întotdeauna sunt sugestive). Vom instala Operatorul Prometheus cu comanda:
$ helm install --name promop --namespace monitoring stable/prometheus-operator -f values.yml
Comanda spune că chartul Prometheus Operator se va instala în clusterul meu cu numele promop, în namespace-ul monitoring și va suprascrie valorile default cu cele din fișierul values.yml.
Ieșirea va fi de forma următoare:
$ helm install --name promop --namespace monitoring stable/prometheus-operator -f values.yml
NAME: promop
LAST DEPLOYED: Fri Jan 25 23:21:42 2019
NAMESPACE: monitoring
STATUS: DEPLOYED
RESOURCES:
==> v1/ServiceMonitor
NAME AGE
promop-prometheus-operator-alertmanager 1s
promop-prometheus-operator-coredns 1s
promop-prometheus-operator-apiserver 1s
promop-prometheus-operator-kube-controller-manager 1s
promop-prometheus-operator-kube-etcd 1s
promop-prometheus-operator-kube-scheduler 1s
promop-prometheus-operator-kube-state-metrics 1s
promop-prometheus-operator-kubelet 1s
promop-prometheus-operator-node-exporter 1s
promop-prometheus-operator-operator 1s
promop-prometheus-operator-prometheus 1s
==> v1/Pod(related)
[...]
Rularea comenzii de mai jos ne va arăta proaspăt instalatul deployment:
$ helm list
NAME REVISION UPDATED STATUS CHART APP VERSION NAMESPACE
promop 1 Fri Jan 25 23:21:42 2019 DEPLOYED prometheus-operator-1.9.0 0.26.0 monitoring
Vom vizualiza toate podurile Operatorului Prometheus:
$ kubectl get pods -n monitoring -owide
NAME READY STATUS RESTARTS AGE IP NODE
alertmanager-promop-prometheus-operator-alertmanager-0 2/2 Running 0 2m30s 172.17.0.6 minikube
prometheus-promop-prometheus-operator-prometheus-0 3/3 Running 1 2m23s 172.17.0.7 minikube
promop-grafana-776b7c9c6-sjwgs 3/3 Running 0 2m34s 172.17.0.4 minikube
promop-kube-state-metrics-5757c5f856-c58c5 1/1 Running 0 2m34s 172.17.0.5 minikube
promop-prometheus-node-exporter-z2vnn 1/1 Running 0 2m34s 192.168.122.56 minikube
promop-prometheus-operator-operator-6fcfb75b68-hvcxr 1/1 Running 0 2m34s 172.17.0.3 minikube
Vizualizăm toate cele 4 CRD instalate:
$ kubectl get crd
NAME CREATED AT
alertmanagers.monitoring.coreos.com 2019-01-25T21:21:42Z
prometheuses.monitoring.coreos.com 2019-01-25T21:21:43Z
prometheusrules.monitoring.coreos.com 2019-01-25T21:21:43Z
servicemonitors.monitoring.coreos.com 2019-01-25T21:21:43Z
Vizualizăm serviciile Operatorului Prometheus:
$ kubectl get svc -n monitoring
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
alertmanager-operated ClusterIP None 9093/TCP,6783/TCP 2m7s
prometheus-operated ClusterIP None 9090/TCP 2m
promop-grafana ClusterIP 10.102.175.10 80/TCP 2m12s
promop-kube-state-metrics ClusterIP 10.106.42.89 8080/TCP 2m12s
promop-prometheus-node-exporter ClusterIP 10.105.15.173 9100/TCP 2m12s
promop-prometheus-operator-alertmanager NodePort 10.104.56.13 9093:30903/TCP 2m11s
promop-prometheus-operator-operator ClusterIP 10.111.102.220 8080/TCP 2m11s
promop-prometheus-operator-prometheus NodePort 10.109.124.161 9090:30090/TCP 2m11s
Observăm că serviciile prin intermediul cărora putem accesa interfața grafică Prometheus și Alertmanager sunt de tipul NodePort și folosesc porturile 30090, respectiv 30903 - exact tipul și portul specificat de noi în fișierul values.yml. În același timp, serviciul prin care putem accesa Grafana este de tipul ClusterIP, așa că ori vom face port-forward, ori putem edita serviciul pentru a-l face accesibil dintr-un browser local și vom schimba tipul serviciului din ClusterIP în NodePort (eventual putem să îi alocăm un port până în 32767 sau să lăsăm Kubernetes să îi atribuie un port oarecare):
$ kubectl edit svc promop-grafana -n monitoring
O nouă comandă kubectl get svc -n monitoring ne va arăta portul local pe care putem accesa Grafana:
$ kubectl get svc -n monitoring | grep grafana
promop-grafana NodePort 10.102.175.10 80:32628/TCP
O altă variantă este să edităm de la început fișierul values.yml cu tipul servciului și portul pe care poate fi accesată Grafana. Posibilități sunt mai multe, totul depinde de intuiția și starea în care se află utilizatorul. 🙂
Cu ajutorul comenzii kubectl cluster-info aflăm informații despre cluster, precum și IP-ul de pe care putem accesa local Prometheus și Alertmanager (asta în cazul în care aveți minikube, căci dacă aveți un cluster K8s cu mașini virtuale, ar trebui să știți deja IP-ul masterului):
$ kubectl cluster-info
Kubernetes master is running at https://192.168.39.54:8443
KubeDNS is running at https://192.168.39.54:8443/api/v1/namespaces/kube-system/services/kube-dns:dns/proxy
În acest moment, dacă scriem în orice browser adresele de mai jos (bineînțeles, schimbați în funcție de valorile voastre), putem accesa:
- la adresa http://192.168.39.54:30090/graph putem vedea Prometheus;
- la adresa http://192.168.39.54:30903 putem accesa Alertmanager;
- la adresa http://192.168.39.54:32628 putem accesa Grafana (de reținut că datele inițiale de logare sunt admin/prom-operator).
În imaginea de mai jos pot fi văzute cele 3 instalări; se observă că vin cu reguli și alerte predefinite:
Prometheus Operator: cum se instalează reguli noi pentru Prometheus
Dacă într-o instalare clasică de Prometheus regulile puteau fi adăugate foarte simplu editând fișierul de configurare /etc/prometheus/prometheus.yaml, Operatorul Prometheus folosește altă metodă: se instalează o nouă resursă de tip PrometheusRule bazată pe definiția CRD-ului prometheusrules.monitoring.coreos.com.
Pentru a vedea ce resurse de acest tip avem în acest moment în cluster, rulăm comanda de mai jos (sunt regulile predefinite care vin la instalarea operatorului):
$ kubectl get prometheusrules.monitoring.coreos.com -n monitoring NAME AGE promop-prometheus-operator-alertmanager.rules 10h promop-prometheus-operator-etcd 10h promop-prometheus-operator-general.rules 10h promop-prometheus-operator-k8s.rules 10h promop-prometheus-operator-kube-apiserver.rules 10h promop-prometheus-operator-kube-prometheus-node-alerting.rules 10h promop-prometheus-operator-kube-prometheus-node-recording.rules 10h promop-prometheus-operator-kube-scheduler.rules 10h promop-prometheus-operator-kubernetes-absent 10h promop-prometheus-operator-kubernetes-apps 10h promop-prometheus-operator-kubernetes-resources 10h promop-prometheus-operator-kubernetes-storage 10h promop-prometheus-operator-kubernetes-system 10h promop-prometheus-operator-node.rules 10h promop-prometheus-operator-prometheus-operator 10h promop-prometheus-operator-prometheus.rules 10h
Ei bine, dorim să putem defini și noi câteva reguli personale. Pentru aceasta, vom face un nou fișier, să-i spunem custom-rules.yaml, asemănător cu cel de mai jos (unde eticheta prometheus se referă la instanța Prometheus instalată conford CRD prometheuses.monitoring.coreos.com, name este numele setului de noi reguli instalate, release este numele release-ului helm instalat aflat cu comanda helm list, iar namespace e de la sine înțeles la ce se referă):
apiVersion: monitoring.coreos.com/v1
kind: PrometheusRule
metadata:
labels:
prometheus: promop-prometheus-operator-prometheus
role: alert-rules
name: custom-rule
namespace: monitoring
release: promop
spec:
groups:
- name: general.rules
rules:
- alert: TargetDown
annotations:
description: '{{ $value }}% of {{ $labels.job }} targets are down.'
summary: Targets are down
expr: 100 * (count(up == 0) BY (job) / count(up) BY (job)) > 10
for: 10m
labels:
severity: warning
Crearea acestui nou set de reguli Prometheus se face cu binecunoscuta comandă:
kubectl create -f custom-rules.yaml
Dacă vom verifica în Prometheus în meniul Alerts, vom vedea aceste noi reguli definite.
Prometheus Operator: cum se editează configurația Alertmanager
Ei bine, toate aceste reguli și alerte predefinite ori definite de noi nu au mare valoare dacă nu declanșează, la un moment dat, și sistemul de alertare, astfel încât cei care monitorizează clusterul să poată ști în orice moment când are loc ceva neobișnuit sau care necesită intervenția umană pentru remediere.
Alertmanager din Prometheus Operator vine cu o singură alertă predefinită, alertă care este un simplu exemplu - DeadMansSwitch (o alertă care, după definirea destinației, ar trebui să se declanșeze automat în cazul în care clusterul Prometheus nu funcționează corect):
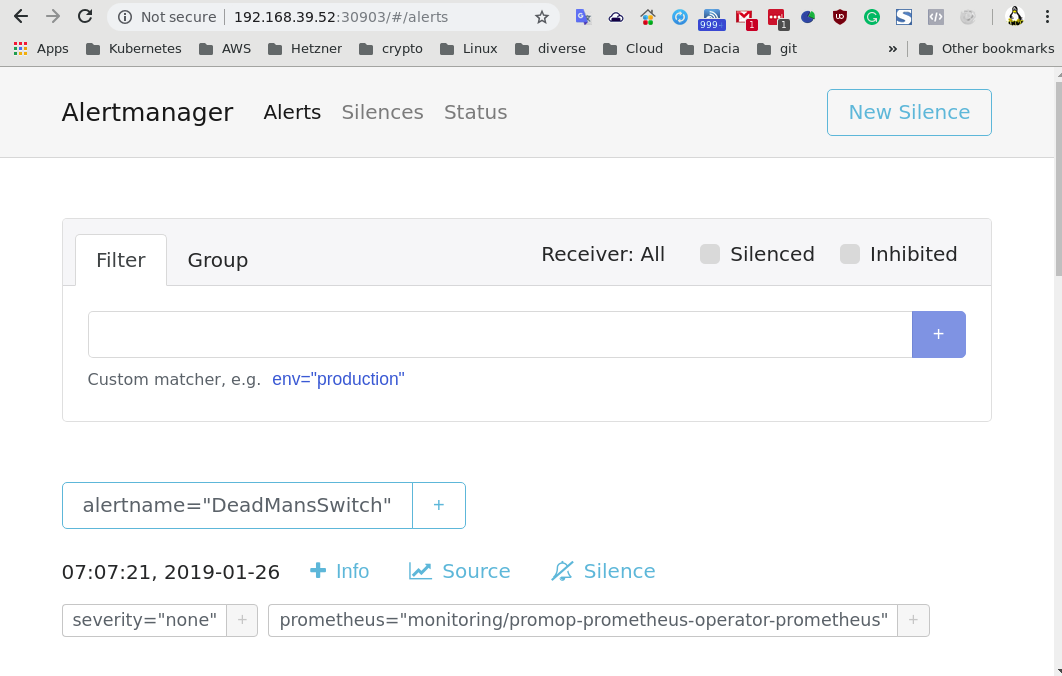
Într-o instalare clasică de alertmanager, aceste alerte (grupuri, adrese de email, etc.) se defineau foarte simplu în fișiserul de configurare /etc/prometheus/alertmanager.yaml. În Prometheus Operator, avem două posibilități în care putem adăuga, șterge, defini alerte ori receptori din Alertmanager:
- Prima modalitate este editarea fișierului values.yaml dat ca parametru în momentul instalării deployment-ului cu helm: undeva, pe la linia 66, avem următorul bloc de text:
66 ## Alertmanager configuration directives
67 ## ref: https://prometheus.io/docs/alerting/configuration/#configuration-file
68 ## https://prometheus.io/webtools/alerting/routing-tree-editor/
69 ##
70 config:
71 global:
72 resolve_timeout: 5m
73 route:
74 group_by: ['job']
75 group_wait: 30s
76 group_interval: 5m
77 repeat_interval: 12h
78 receiver: 'null'
79 routes:
80 - match:
81 alertname: DeadMansSwitch
82 receiver: 'null'
83 receivers:
84 - name: 'null'
După editarea și salvarea acestui fișier, este foarte simplu să actualizăm implementarea noastră de Prometheus Operator cu comanda:
helm upgrade -f values.yaml promop stable/prometheus-operator --namespace monitoring
Putem vedea schimbările apărute în Alertmanager în meniul Status/Config.
- A doua modalitate de a edita configurația Alertmanager în Prometheus Operathos (și care îmi place mie foarte mult), este folosirea comenzii
kubectl get secretpentru a vedea configurația actuală a Alertmanager:
Căutăm numele secretului:
kubectl get secrets -n monitoring
NAME TYPE DATA AGE
alertmanager-promop-prometheus-operator-alertmanager Opaque 1 11h
Citim configurația actuală Alertmanager (ar trebui să aveți instalat jq):
kubectl get secret -n monitoring alertmanager-promop-prometheus-operator-alertmanager -ojson | jq -r '.data["alertmanager.yaml"]' | base64 -d
Pentru a trimite această configurație într-un fișier editabil:
kubectl get secret -n monitoring alertmanager-promop-prometheus-operator-alertmanager -ojson | jq -r '.data["alertmanager.yaml"]' | base64 -d > alertmanager.yaml
După editarea fișierului alertmanager.yaml, aplicăm noua configurație folosind comanda:
kubectl -n monitoring create secret generic alertmanager-promop-prometheus-operator-alertmanager --from-literal=alertmanager.yaml="$(< alertmanager.yaml)" --dry-run -oyaml | kubectl -n monitoring replace secret --filename=-
Asta este tot! Am definit și declanșarea alertelor în Alertmanager instalat în Prometheus Operator!
Trimiterea alertelor Alertmanager via Gmail
Alertmanager nu este server SMTP, dar poate trimite emailurile către un server de email.
Să presupunem că nu aveți instalat un server de mail sau nu doriți să vă bateți capul cu așa ceva - exemplul cel mai elocvent este minikube. Cum puteți testa funcționalitatea alertelor, corectitudinea configurării și trimiterea de emailuri? Foarte simplu: stabilim ca Alertmanager să trimită emailurile de alertare prin intermediul unui cont de Gmail!
Sunt necesari câțiva pași simpli pentru configurarea serviciului:
- în primul rând trebuie să obținem un token, căci nimeni nu dorește să-și pună parola contului Google într-un fișier - click pe How to generate an App paswword și urmați pașii indicați (conectare în contul Google - Securitate - Parole pentru aplicații - Selectați aplicația - click pe Generare) ; puneți un nume sugestiv la aplicație, de exemplu Alertmanager. Atenție! Pentru generarea unui token de aplicație este necesară activarea verificării în doi pași pentru contul Google!
- completați secțiunea global a fișierului de configurare Alertmanager cu următoarele elemente:
global:
resolve_timeout: 5m
smtp_require_tls: true
smtp_from: [email protected]
smtp_smarthost: smtp.gmail.com:587
smtp_auth_username: [email protected]
smtp_auth_identity: [email protected]
smtp_auth_password: token_generat
Aici - click am expus modalitatea de a configura Alertmanager prin a doua metodă, folosind un cont de Gmail (din păcate, nu funcționează integrarea în WordPress, așa cum promit cei de la asciinema).
Lasă un răspuns